実験の結果が、参加者ごとにCSVファイルとして保存されることがあります。そしてそのCSVファイルでは、各行が1試行(trial)に対応していることが多いと思います。
実際の分析では、各条件ごとに平均値などを算出し、各行が参加者に対応したデータ(ファイル)が欲しいことがありますよね。例えば以下のようなデータです。

図1.最終的に欲しいデータの形
ここでは、Rを使って複数のCSVファイルを読み込み、上のようなデータを作成する方法を解説します。なお、解説しているコードとサンプルデータはGitHubからダウンロードいただけます。
まず、分析対象のデータ(ひとり分)は次のような構成になっています。
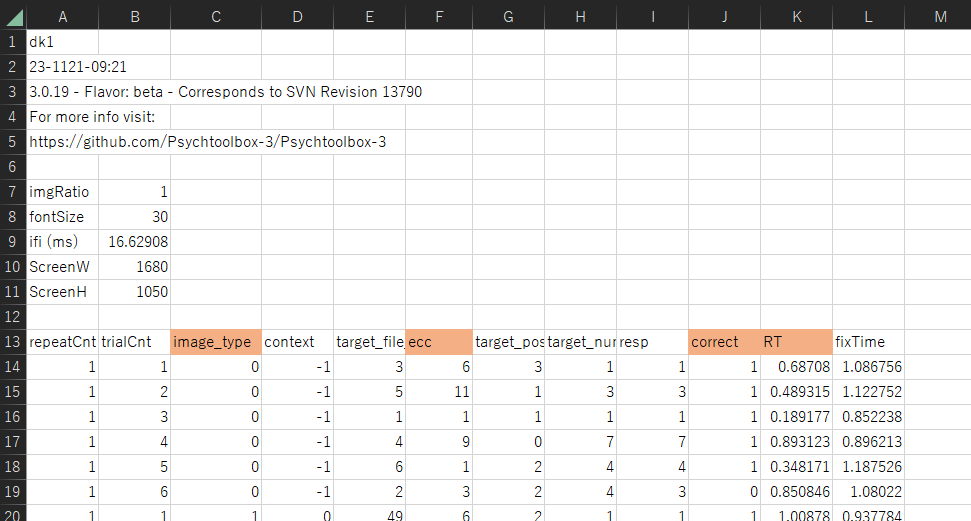
図2.ひとり分のデータ
1行目から12行目までは、分析とは直接関係のないデータが含まれています。13行目はデータの見出しです。image_typeは、0, 1, 2のいずれかの値を取ります。図1の条件Aに該当します。なお、image_typeが0のデータは練習試行のデータなので分析からは除外します。eccは、1, 3, 6, 9, 11のいずれかの値を取る実験条件を表しています。図1の条件Bに該当します。
correctは、その試行で正解していたら1、間違っていたら0となります。RTは反応時間です。
Rの設定
Rを使って集計作業を行います。Rのインストール方法についてはいろいろなページで解説されているので割愛します。Rだけでなく、RStudioもインストールしておくとよいと思います。RStudioのサイトには、R単体へのリンクもありますので、こちらの手順に従って両方をインストールするとよいと思います。
Rのコードを取得して作業ディレクトリを変更
GitHubからコードをダウンロードしてください。ダウングレードしたzipファイルは、すべて展開(解凍)してください。(本記事とは無関係のファイルが含まれています)
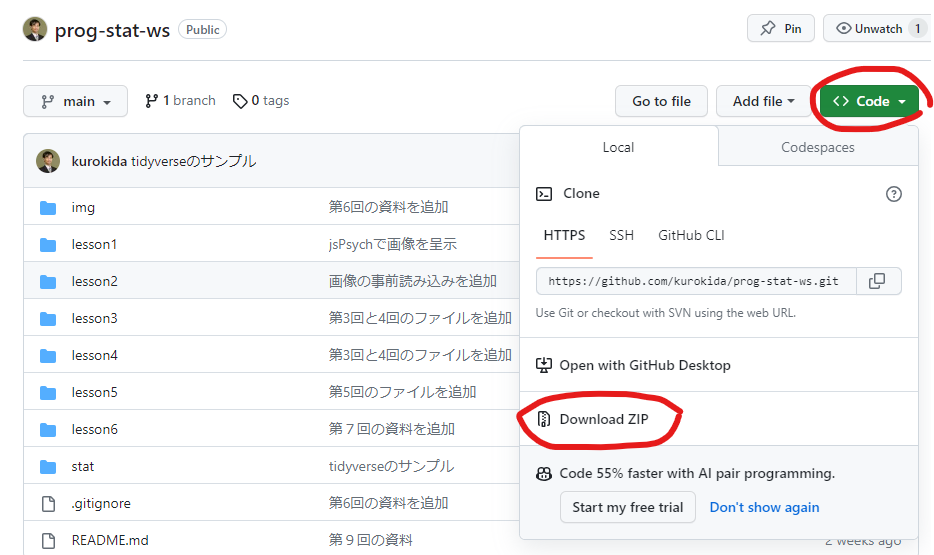
展開したフォルダの中の、statフォルダにある「複数のCSVファイルを読み込んで集計.R」が今回ご紹介する内容です。なお、csv_filesフォルダに分析対象のCSVファイルを保存するようにしてください。サンプルとして2つのファイルが保存されています。
「複数のCSVファイルを読み込んで集計.R」を開いたら、Session -> Set working directory -> To source file location を実行してください。これによって作業ディレクトリがRファイルが保存されている場所に変更されます。
tidyverseのインストール
ここではtidyverseの機能を使って集計を行います。インストールしていない場合は次のコマンドでインストールできます(1回だけでよい作業です)
install.packages("tidyverse") # tidyverseをインストールするときだけ必要tidyverseを読み込んで利用可能な状態にします。
library(tidyverse)次に分析に使用しないデータの行数を設定します。先述の通り、今回のCSVファイルは、13行目が見出しになっているため、12を設定します。
skip_row_num = 12 # 重要! 必ず、自分のデータに適した数字にしてください。CSVファイルを保存している場所についての設定です。フォルダ名(csv_files)は変更可能です。
current_directory <- getwd() # 現在のディレクトリ(フォルダ)
data_directory <- paste(current_directory, "csv_files", sep = "/")CSVファイルの一覧を取得します。pattern = “\\.csv$”については深く理解する必要はなく、csvファイルを指定しているという理解で大丈夫です。興味があれば、エスケープ文字、正規表現、などで検索してもらうとよいと思います。
file_list <-
list.files(path = data_directory,
pattern = "\\.csv$",
full.names = TRUE)ひとつのデータフレームにまとめる
複数のCSVファイルのデータを、単一のデータフレーム(all_data)に保存します。また今回のCSVファイルには参加者を識別する情報が含まれていなかったため、参加者番号(participant_ID )を付与しています。for文を使って、CSVファイルの数だけ繰り返します。%>%の記号はパイプ演算子と呼ばれ、tidyverseの機能のひとつです。パイプ演算子の左側の結果が、パイプ演算子の右側に渡されます。
all_data <- NULL # 全員分のデータをひとつのデータフレーム(tibble)に集約します
id <- 1 # 参加者にidを割り当てることにします。CSVファイルに参加者識別情報がある場合は不要
for (file_name in file_list) {
# csvファイルの数だけ読み込みを繰り返します
print(file_name)
tmp_data <-
read.csv(file_name, skip = skip_row_num, header = TRUE)
tmp_data <- tmp_data %>% mutate(participant_ID = id) # id情報(列)を追加
id <- id + 1 # idの加算
all_data <- bind_rows(all_data, tmp_data) # すでに読み込んだデータに加える
}Xでおやまさんより大変有意義な方法を教えていただきました! 上のfor文とほぼ同じことを、たった1行で実現できます! ただし、参加者番号はCSVファイルの名前(絶対パス)になります。また各ファイルに対して、少し凝った作業をしたいときには、上記のfor文のほうが使い勝手がよいこともありそうです。
all_data <- read_csv(file_list, skip = skip_row_num, col_names = TRUE, id = "participant_ID")条件ごとの平均反応時間
all_dataには練習試行のデータが含まれているので、それを取り除きます。その後、participant_ID, image_type, eccの3つでグループ化し、グループごとに平均値を算出します。
このままだとデータが縦方向に並んでしまいます。私たちが最終的に欲しいのは図1のような形なので、pivot_wider関数を使って横向きにデータを変換します。names_from で横に並べたい列の情報を、values_from で分析対象(反応時間の平均値)を指定します。
rt_data <- all_data %>%
filter(image_type != 0) %>% # 練習のデータを取り除く
group_by(participant_ID, image_type, ecc) %>% # かっこの中はグループ化したい順番
summarise(mean_RT = mean(RT)) %>% # グループごとの平均値を計算
pivot_wider(names_from = c(image_type, ecc),
values_from = mean_RT)
rt_dataは図1のデータに対応しています。これをCSVファイルとして新たに保存するには、次のようにします。
write.csv(rt_data, "rt_data.csv", row.names = FALSE) # 集計結果をcsvファイルとして出力することができます。条件ごとの正答率
サンプルデータでは各試行で正解したかどうかの情報はcorrect列に保存されており、correct=1が正解を意味します。正答率は、各条件ごとに正解した数を条件の試行数で割ることで求められます。
correct_rate_data <- all_data %>%
filter(image_type != 0) %>% # 練習のデータを取り除く
group_by(participant_ID, image_type, ecc) %>% # かっこの中はグループ化したい順番
summarise(correct_rate = sum(correct == 1) / length(correct)) %>% # 正答率
pivot_wider(names_from = c(image_type, ecc),
values_from = correct_rate)説明は以上となりますが、サンプルコードではさらにSTEP3,4として、group_nestとmap関数を使用する方法を載せています。平均値や正答率よりも複雑な計算を条件ごとに行う場合の参考にしてください。西山慧先生による解説もとても勉強になります。
それから、意図した通りに集計できているかを、ひとり分のデータを使ってエクエルなどで計算し、結果が一致することを確認することをお勧めします。