
ここでは、社会心理学のための統計学(清水裕士先生、荘島宏二郎先生)の単回帰分析(P57~)について、HADを使って計算する方法を解説しています。あわせてRを使って、HADの出力結果との比較を行っています。
データは、こちらからダウンロードできます。ここでは第4章のCSVファイルをダウンロードします。
CSVファイルのデータをすべてコピーして、HADのデータシートに貼り付けます。以下のようになります。ただし、データは一部しか表示されていませんのでご注意ください。
データの読みこみと、使用変数についてはこちらで解説しています。
モデリングシートは以下のようになります。
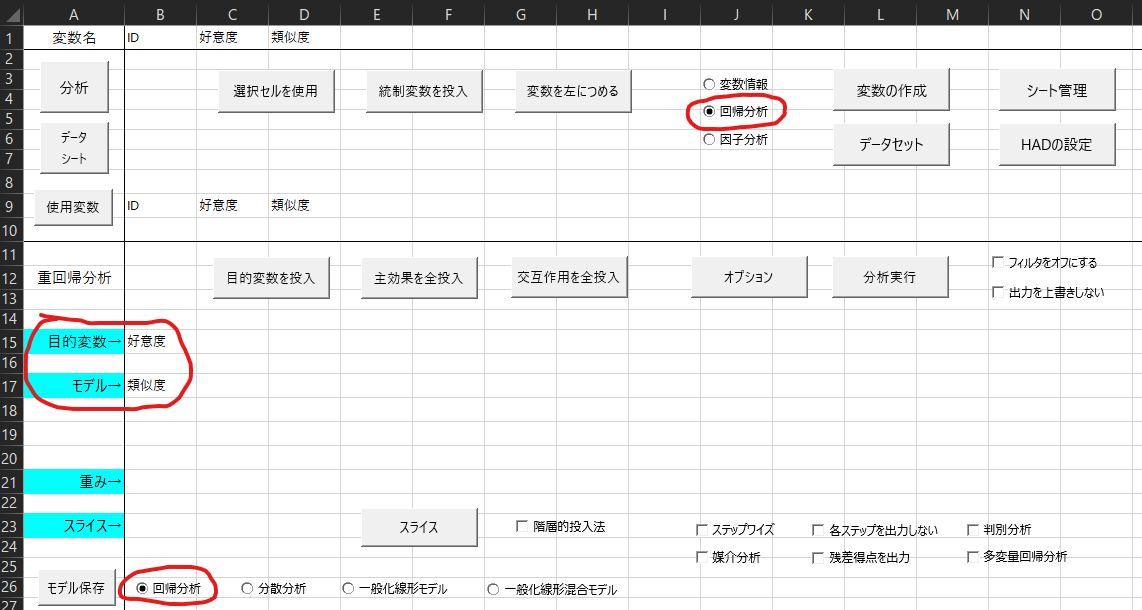
少し分かりにくいところとしては「目的変数」と「モデル」の部分かと思います。それぞれに、直接「好意度」「類似度」と書き込んでもよいですが、使用変数の好意度を選択した状態で「目的変数を投入」をクリックすると便利です。

続けて「主効果を全投入」をクリックすると、モデルのところに「類似度」が自動で入ります。
最後に「分析実行」をクリックします。
結果として次のようなものが得られます。
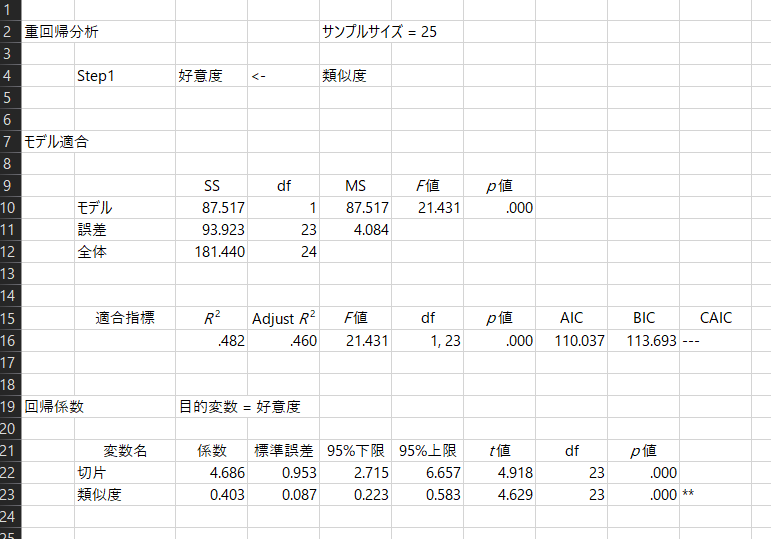
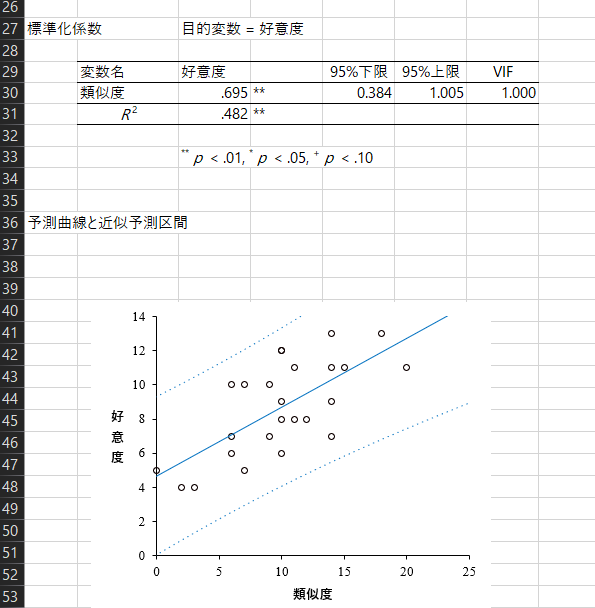
HADについての説明は以上ですが、ここではRを使って、もう少し理解を深めてみましょう。
まず、Rで回帰分析をするだけであれば、非常に簡単で次のコマンドを実行するだけです。これらのコマンドは、HAD2Rを使えばすぐに確認できます。
dat <- read.csv("CSVファイルの指定")
subdat <- subset(dat, select = c(好意度,類似度))
result <- lm(好意度~類似度, subdat)
summary(result)ではあえて回帰係数を算出してみましょう。(といっても、covやvarなどの便利な関数を使っていますが・・・)
まずは回帰直線の傾き(類似度の係数)です。
a <- cov(subdat$好意度, subdat$類似度) # 説明変数と目的変数の共分散
b <- var(subdat$類似度) # 説明変数の分散
coef <- a/b # 標本回帰係数(傾き)同様に切片を算出してみます。
intercept <- mean(subdat$好意度) - coef * mean(subdat$類似度)このあたりの説明は書籍に詳しくありますのでぜひ参照してください。
次に標本回帰係数を使って説明変数から目的変数を予測してみます。
predicted <- coef * subdat$類似度 + intercept # 予測値この予測値と実際に得られたデータとのずれを残差(residual)と言います。残差は次のように求めることができます。
residual <- subdat$好意度 - predicted # 残差ここで、残差平方和(Residual Sum of Squares)を計算してみましょう。
RSS <- sum(residual^2)残差と残差平方和は、書籍のP65 表4-3 予測値と残差得点に記述があります。同じ値が得られていることを確認してください。残差平方和は、HADの結果としては誤差のSSとして出力されています。
回帰平方和を算出して、モデルの適合度を示すF値を算出してみましょう。
SS <- sum((predicted - mean(subdat$好意度))^2) # 回帰平方和(HADのモデルのSS)
df <- length(subdat$類似度) - 2 # 自由度 (n-2) この例では23になる
variance <- RSS/df # HADの誤差のMS
F_value <- SS/variance # HADのモデル適合のF値
次に回帰係数(傾き)の標準誤差を算出してみましょう。なぜ以下の数式で算出できるかに興味のあるかたは、浅野晃先生の資料が分かりやすいです。
c <- sum((subdat$類似度 - mean(subdat$類似度))^2) # 類似度の平方和
df <- length(subdat$類似度) - 2 # 自由度 (n-2)
d <- RSS/df # 不偏分散
se_coef <- sqrt(d/c) # 類似度の回帰係数の標準誤差ちなみに、dの値は、HADの結果の誤差のMSに出力されています。se_coef(類似度の回帰係数の標準誤差)も同様にHADの結果に出力されています。
切片の標準誤差についてはこちらに説明があります。cが類似度の平方和、dが残差の不偏分散である点に注意してください(上式を参照のこと)。
tmp <- (1/length(subdat$類似度) + mean(subdat$類似度)^2/c)*d
sqrt(tmp)
書籍のP62, 4.2.3 回帰係数の信頼区間について。まず想定しているt分布(自由度23)の95%臨界点を求めましょう。5%が両側に分かれて2.5%になっている点に注意してください。qt関数の結果(つまりq)は負の数であることにも注意が必要です。
q <- qt(0.025, df) # -2.07
coef + q * se_coef # 95%下限
coef - q * se_coef # 95%下限類似度の回帰係数について、t値を求めるには、
t_value <- coef/se_coef # 4.63このt値よりも大きな値を取るような確率を両側で求めると、
pt(t_value, df, lower.tail = FALSE) * 2 # 0.0001172248(2倍しているのは両側だから)と非常に小さな値になり、帰無仮説(類似性の母回帰係数は0ではない)が棄却されます。あるいは、求めたt値(4.63)が95%臨界点(2.07)よりも大きいことから棄却することもできます。
決定係数は次の計算式で求められます。
var(predicted)/var(subdat$好意度)あるいは決定係数は目的変数と説明変数の相関係数の二乗と等しいので次のように求めることも可能です。
r <- cor(subdat$好意度, subdat$類似度)
r^2