
まず、共分散とはなに?という人は、高校数学の美しい物語 共分散の意味と簡単な求め方をご覧ください。ここでは、HADとRを使って、どのように相関係数と共分散を求めるのかについて説明します。また以下の説明では、「高校数学の~」と同じデータを使って解説しています。
HADを使って
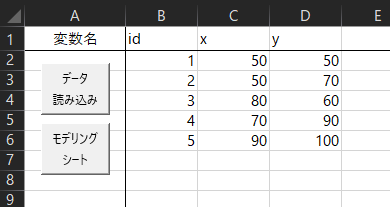
「高校数学の~」と同じデータを読み込んだところです。
モデリングシートに移って「使用変数」をクリックして「全投入」します。
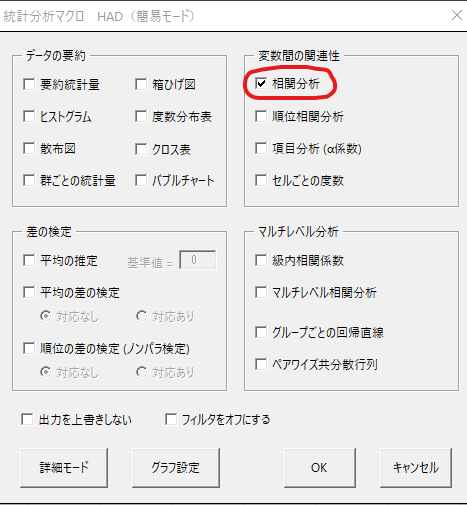
「分析」をクリックして「相関分析」にチェックを入れます。
相関係数は、0.634となります。
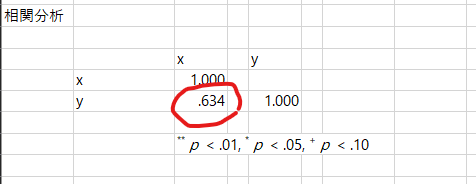
共分散は235です。
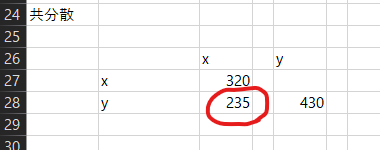
「高校数学の~」サイトで共分散が計算されていますが、それによれば188となっています。おかしいですね、一致していません。答えを書いてしまうと、HADでは共分散の計算過程で(n-1)で割っているためです。Bell Curveの統計WEBの説明が分かりやすいですが、ここではRで計算することで、もう少し詳しく見ていきたいと思います。
Rを使って
データを読み込みます。
x <- c(50, 50, 80, 70, 90)
y <- c(50, 70, 60, 90, 100)相関係数を求めます。
cor(x, y)HADと同じく、0.634が得られると思います。
次に、共分散を求めます。
cov(x, y)たぶん、235になります。これはHADの結果と一致しています。ちなみに、
var(x, y)も同じく235になります。
では「高校数学の~」と同じ方法で計算してみましょう。
dev_x <- x-mean(x)
dev_y <- y-mean(y)
a <- dev_x * dev_y
b <- sum(a)
cov1 <- b/length(x)cov1の値が188になって「高校数学の~」と同じ共分散の値になったと思います。length(x)は分かりやすく言えばデータの数です。教科書などでよく「n」と表されます。
では次の計算結果はどうなるでしょうか。
cov2 <- b/(length(x)-1)cov2は235になります。つまり、HADやRのcov(x,y)と同じ結果です。なにをしているか式をよく見ると、「n-1」で割っていますね。分析対象のデータが母集団とみなせる場合には「n」で割ればよいのですが、私たちの研究では通常「標本」を分析対象とし、不偏推定量に関心があるため「n-1」で割った値を使用することが多くなります。